Diebold, Gunther, and Tay (1998) propose a way to evaluating density forecasts. The basic
idea is that since under the null hypothesis the forecasts are equal to the true densities
(conditioned on past information), applying the cumulative distribution function (the
probability integral transform or PIT) to the series of observations should yield a series of iid
uniform-
variables. Whether the transformed variables are iid uniform can be checked in various ways.
Diebold, Gunther, and Tay (1998) suggest plotting histograms and autocorrelation functions
to visualize the quality of the density forecasts.
In order to apply the PIT to our predicted recovery rate densities, we create a vector
in
which we stack all recovery rate observations. For each element in the vector, we can now
create a conditional density forecast from our estimated model.
Applying the cumulative distribution function associated with these density forecasts to the
vector
yields a vector of transformed variables. Under the null hypothesis that the density forecasts
are correct, the elements of the vector of transformed variables should be an iid uniform
series. Serial correlation of the series would indicate that we have not correctly conditioned
on the relevant information. A departure from uniformity would indicate that the marginal
distributions are inappropriate.
D Supplementary tables
Table 1:
Recovery Rate Statistics by Year
This table reports some annual statistics for the data used in the paper. First column figuresare issuer-weighted default rates of US bond issuers provided by Moody’s. The other threecolumns are the number of default events, and the mean and standard deviation for recoveryrates in the Altman data.
Year
1981
0.17%
1
12.00
-
1982
1.08%
12
39.51
14.90
1983
1.02%
5
48.93
23.53
1984
0.98%
11
48.81
17.38
1985
1.01%
16
45.41
21.87
1986
2.07%
24
36.09
18.82
1987
1.65%
20
53.36
26.94
1988
1.52%
30
36.57
17.97
1989
2.43%
41
43.46
28.78
1990
4.14%
76
25.24
22.28
1991
3.55%
95
40.05
26.09
1992
1.85%
35
54.45
23.38
1993
1.13%
21
37.54
20.11
1994
0.80%
14
45.54
20.46
1995
1.25%
25
42.90
25.25
1996
0.77%
19
41.90
24.68
1997
0.89%
25
53.46
25.53
1998
1.60%
34
41.10
24.56
1999
2.61%
102
28.99
20.40
2000
3.43%
120
27.51
23.36
2001
4.98%
157
23.34
17.87
2002
3.33%
112
30.03
17.18
2003
2.36%
57
37.33
23.98
2004
1.28%
39
47.81
24.10
2005
1.12%
33
58.63
23.46
Table 2:
Recovery Rates by Seniority and Industry
Panel A: Number of observations and the mean and standard deviation of recovery rates in our sampleclassified by seniority, for the whole sample (all default events), for default events for which we only observerecovery on a single instrument (with only one seniority), and for default events for which we observerecoveries on at least two different seniorities. Panel B: Number of observations and the mean and standard deviation of recovery rates in our sampleclassified by industry.
Panel A: Recovery Ratesby Seniority
Seniority
All default events
Senior Secured
203
42.08
25.48
Senior Unsecured
366
36.88
23.29
Senior Subordinated
326
32.90
23.77
Subordinated
154
34.51
23.05
Discount
75
21.29
18.48
Default events with single recovery
Senior Secured
145
39.29
23.35
Senior Unsecured
239
36.45
22.45
Senior Subordinated
209
34.52
23.30
Subordinated
87
37.86
20.22
Discount
29
21.72
19.67
Default events with multiple recoveries
Senior Secured
58
49.04
29.25
Senior Unsecured
127
37.68
24.87
Senior Subordinated
117
30.00
24.42
Subordinated
67
30.16
25.79
Discount
46
21.03
17.91
Panel B: Recovery Ratesby Industry
Industry
Building
10
33.56
36.24
Consumer
149
35.66
22.21
Energy
47
36.47
16.66
Financial
95
35.60
25.54
Leisure
69
41.43
29.40
Manufacturing
395
35.08
23.83
Mining
14
35.52
17.50
Services
65
34.16
28.09
Telecom
169
29.43
20.90
Transportation
66
38.07
23.79
Utility
23
51.34
27.97
Others
22
37.94
19.30
Table 3:
Parameter estimates (2)
Parameter estimates and measures of fit for various models thatdiffer in the combination of variables that influence the hazard rateand the two parameters of the beta distribution and .Note that with the specification of Shumway (2001), a positive coefficient on a explanatory variable forimplies that falls when the variable rises. sen2, sen3, sen4, sen5 are seniority dummies for Senior Unsecured, SeniorSubordinated, Subordinated and Discount respectively, mult is a dummy that is one for observationscorresponding to default events for which we observe multiple recoveries, cycle is the unobservedcredit cycle, and lagged def. rate and rec. rates are the previous annual default rate and meanrecovery rate respectively. indB and indC are dummies corresponding to industry groups B and C.denotes individual significance at 5%.
M2a
M2b
M5
M6
Default Rates
constant
3.36
3.85
3.36
3.41
cycle
1.04
1.05
1.03
lagged def. rate
-1.20
Recovery Rates
constant
0 .
40
1 .
00
0 .
52
1 .
48
0 .
34
1 .
15
0 .
38
1 .
53
sen2
0 .
04
0 .
15
-0 .
02
0 .
10
-0 .
06
-0 .
09
-0 .
07
-0 .
07
sen3
-0 .
18
0 .
00
-0 .
16
-0 .
02
-0 .
35
-0 .
40
-0 .
30
-0 .
32
sen4
0 .
34
0 .
38
0 .
54
1 .
11
0 .
06
0 .
01
-0 .
04
-0 .
11
sen5
-0 .
32
0 .
47
-0 .
23
0 .
32
-0 .
32
0 .
19
-0 .
23
0 .
45
mult
-0 .
22
-0 .
56
-0 .
39
-0 .
54
-0 .
29
-0 .
49
-0 .
26
-0 .
56
multsen2
-0 .
21
-0 .
26
0 .
00
0 .
03
-0 .
18
-0 .
35
-0 .
25
-0 .
40
multsen3
-0 .
14
-0 .
08
-0 .
72
-0 .
57
-0 .
28
-0 .
17
-0 .
22
-0 .
05
lagged rec. rate
0 .
37
-0 .
40
cycle
0 .
18
-0 .
65
0 .
48
-0 .
44
0 .
55
-0 .
63
cyclesen2
0 .
08
0 .
15
-0 .
15
0 .
13
-0 .
01
0 .
29
cyclesen3
-0 .
25
-0 .
01
-0 .
26
0 .
25
-0 .
20
0 .
26
cyclesen4
-0 .
46
-0 .
56
-0 .
09
0 .
41
0 .
20
0 .
79
cyclesen5
-0 .
5
-0 .
16
-0 .
46
-0 .
14
-0 .
72
-0 .
61
cyclemult
0 .
67
0 .
31
0 .
65
0 .
20
0 .
73
0 .
35
cyclemultsen2
-0 .
49
-0 .
42
0 .
06
0 .
22
-0 .
03
0 .
10
cyclemultsen3
0 .
76
0 .
80
0 .
52
0 .
42
0 .
34
0 .
20
cyclelagged rec. rate
-0 .
39
0 .
44
indB
0 .
29
0 .
43
indC
0 .
09
0 .
40
Transition Prob.
p
0.8487
0.9523
0.8742
0.8232
q
0.7872
0.7634
0.7432
0.6443
Measuresof Fit
Log Likelihood
131.726
91.214
202.032
193.003
AIC
-221.45
-110.43
-322.06
-302.01
BIC
-0.1344
0.0695
-0.1395
-0.1118
E Supplementary Figures
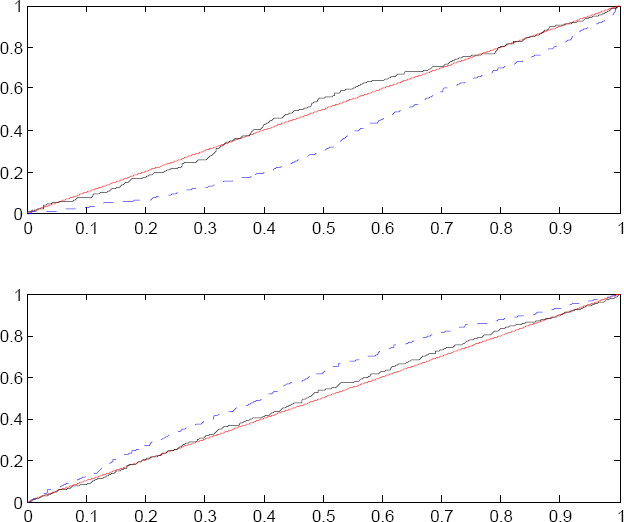
Figure 1:
Q-Q plots of the PIT series of the static and cycle models.
Dashed line is the static model (M1), solid line is a dynamic model (M2). The upper panelis a Q-Q plot for periods which are identified as upturn by the dynamic model, the lowerpanel is a Q-Q plot for periods which are identified as downturns by the dynamic model.
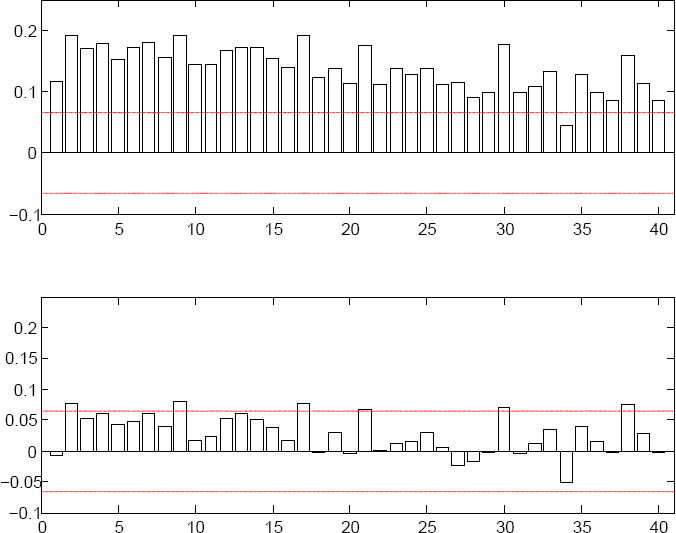
Figure 2:
Correlograms of the PIT series of the static and cycle model.
Upper panel is the correlogram of the static model (M1), the lower panel is the correlogramof a dynamic model (M2). Horizontal lines are 5% two-sided confidence intervals for a singleautocorrelation coefficient.
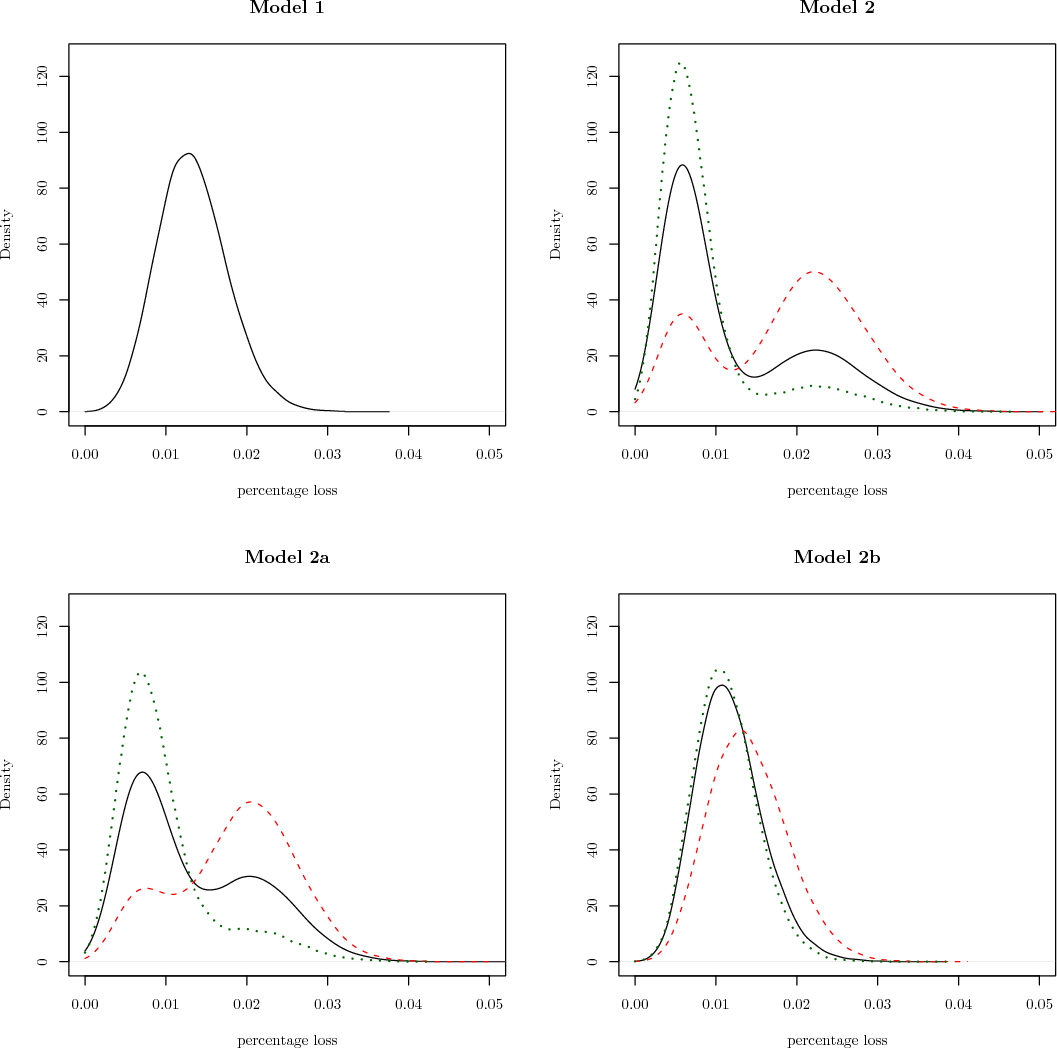
Figure 3:
Loss densities for Models 1, 2, 2a, and 2b
Loss densities for Models 1, 2, 2a and 2b. The solid black line is the unconditional lossdensity (i.e. assuming the probability of being in an upturn is equal to the unconditionalprobability), dotted green line is the upturn loss density (probability of being in upturn of1), the red dashed line is the downturn loss density (probability of being in upturn of 0).
References
Diebold, F. X., T. A. Gunther, and A. S. Tay, 1998, “Evaluating Density Forecasts
with Applications to Financial Risk Management,” International Economic Review,
39, 863–883.
Shumway, T., 2001, “Forecasting Bankruptcy More Accurately: A Simple Hazard
Model,” Journal of Business, 74, 101–124.